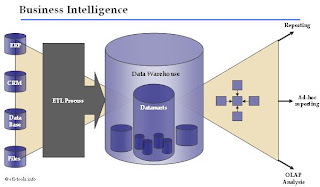
Data Warehouse is a central managed and integrated database containing data from the operational sources in an organization (such as SAP, CRM, ERP system). It may gather manual inputs from users determining criteria and parameters for grouping or classifying records.
That database contains structured data for query analysis and can be accessed by users. The data warehouse can be created or updated at any time, with minimum disruption to operational systems. It is ensured by a strategy implemented in a ETL process.
A source for the data warehouse is a data extract from operational databases. The data is validated, cleansed, transformed and finally aggregated and it becomes ready to be loaded into the data warehouse.
Data warehouse is a dedicated database which contains detailed, stable, non-volatile and consistent data which can be analyzed in the time variant.
Sometimes, where only a portion of detailed data is required, it may be worth considering using a data mart. A data mart is generated from the data warehouse and contains data focused on a given subject and data that is frequently accessed or summarized.
Keeping the data warehouse filled with very detailed and not efficiently selected data may lead to growing the database to a huge size, which may be difficult to manage and unusable. A good example of successful data management are set-ups used by the leaders in the field of telecoms such as O2 broadband. To significantly reduce number of rows in the data warehouse, the data is aggregated which leads to the easier data maintenance and efficiency in browsing and data analysis.
Key Data Warehouse systems and the most widely used database engines for storing and serving data for the enterprise business intelligence and performance management:
Teradata
SAP BW - Business Information Warehouse
Oracle
Microsoft SQL Server
IBM DB2
SAS
=====================================================================================
DataWarehouse ArchitectureThe main difference between the database architecture in a standard, on-line transaction processing oriented system (usually ERP or CRM system) and a DataWarehouse is that the system’s relational model is usually de-normalized into dimension and fact tables which are typical to a data warehouse database design.
The differences in the database architectures are caused by different purposes of their existence.
In a typical OLTP system the database performance is crucial, as end-user interface responsiveness is one of the most important factors determining usefulness of the application. That kind of a database needs to handle inserting thousands of new records every hour. To achieve this usually the database is optimized for speed of Inserts, Updates and Deletes and for holding as few records as possible. So from a technical point of view most of the SQL queries issued will be INSERT, UPDATE and DELETE.
Opposite to OLTP systems, a DataWarehouse is a system that should give response to almost any question regarding company performance measure. Usually the information delivered from a data warehouse is used by people who are in charge of making decisions. So the information should be accessible quickly and easily but it doesn't need to be the most recent possible and in the lowest detail level.
Usually the data warehouses are refreshed on a daily basis (very often the ETL processes run overnight) or once a month (data is available for the end users around 5th working day of a new month). Very often the two approaches are combined.
The main challenge of a DataWarehouse architecture is to enable business to access historical, summarized data with a read-only access of the end-users. Again, from a technical standpoint the most SQL queries would start with a SELECT statement.
In Data Warehouse environments, the relational model can be transformed into the following architectures:
Star schema
Snowflake schema
Constellation schema
Star schema architecture
Star schema architecture is the simplest data warehouse design. The main feature of a star schema is a table at the center, called the fact table and the dimension tables which allow browsing of specific categories, summarizing, drill-downs and specifying criteria.
Typically, most of the fact tables in a star schema are in database third normal form, while dimensional tables are de-normalized (second normal form).
Despite the fact that the star schema is the simpliest datawarehouse architecture, it is most commonly used in the datawarehouse implementations across the world today (about 90-95% cases).
Fact table
The fact table is not a typical relational database table as it is de-normalized on purpose - to enhance query response times. The fact table typically contains records that are ready to explore, usually with ad hoc queries. Records in the fact table are often referred to as events, due to the time-variant nature of a data warehouse environment.
The primary key for the fact table is a composite of all the columns except numeric values / scores (like QUANTITY, TURNOVER, exact invoice date and time).
Typical fact tables in a global enterprise data warehouse are (usually there may be additional company or business specific fact tables):
sales fact table - contains all details regarding sales
orders fact table - in some cases the table can be split into open orders and historical orders. Sometimes the values for historical orders are stored in a sales fact table.
budget fact table - usually grouped by month and loaded once at the end of a year.
forecast fact table - usually grouped by month and loaded daily, weekly or monthly.
inventory fact table - report stocks, usually refreshed daily
Dimension table
Nearly all of the information in a typical fact table is also present in one or more dimension tables. The main purpose of maintaining Dimension Tables is to allow browsing the categories quickly and easily.
The primary keys of each of the dimension tables are linked together to form the composite primary key of the fact table. In a star schema design, there is only one de-normalized table for a given dimension.
Typical dimension tables in a data warehouse are:
time dimension table
customers dimension table
products dimension table
key account managers (KAM) dimension table
sales office dimension table
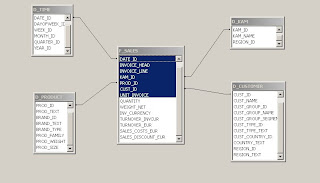
Star schema example
An example of a star schema architecture is depicted below.
Snowflake Schema architecture
Snowflake schema architecture is a more complex variation of a star schema design. The main difference is that dimensional tables in a snowflake schema are normalized, so they have a typical relational database design.
Snowflake schemas are generally used when a dimensional table becomes very big and when a star schema can’t represent the complexity of a data structure. For example if a PRODUCT dimension table contains millions of rows, the use of snowflake schemas should significantly improve performance by moving out some data to other table (with BRANDS for instance).
The problem is that the more normalized the dimension table is, the more complicated SQL joins must be issued to query them. This is because in order for a query to be answered, many tables need to be joined and aggregates generated.
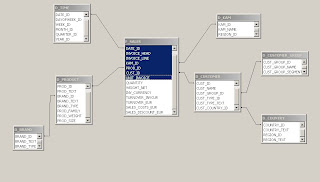
An example of a snowflake schema architecture is depicted below.
Fact constellation schema architecture
For each star schema or snowflake schema it is possible to construct a fact constellation schema.
This schema is more complex than star or snowflake architecture, which is because it contains multiple fact tables. This allows dimension tables to be shared amongst many fact tables.
That solution is very flexible, however it may be hard to manage and support.
The main disadvantage of the fact constellation schema is a more complicated design because many variants of aggregation must be considered.
In a fact constellation schema, different fact tables are explicitly assigned to the dimensions, which are for given facts relevant. This may be useful in cases when some facts are associated with a given dimension level and other facts with a deeper dimension level.
Use of that model should be reasonable when for example, there is a sales fact table (with details down to the exact date and invoice header id) and a fact table with sales forecast which is calculated based on month, client id and product id.
In that case using two different fact tables on a different level of grouping is realized through a fact constellation model.
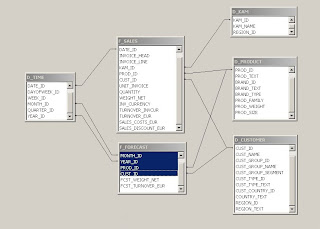
An example of a constellation schema architecture is depicted below.
Fact constellation schema DW architecture
====================================================================================
Data martData marts are designated to fulfill the role of strategic decision support for managers responsible for a specific business area.
Data warehouse operates on an enterprise level and contains all data used for reporting and analysis, while data mart is used by a specific business department and are focused on a specific subject (business area).
A scheduled ETL process populates data marts within the subject specific data warehouse information.
The typical approach for maintaining a data warehouse environment with data marts is to have one Enterprise Data Warehouse which comprises divisional and regional data warehouse instances together with a set of dependent data marts which derive the information directly from the data warehouse.
It is crucial to keep data marts consistent with the enterprise-wide data warehouse system as this will ensure that they are properly defined, constituted and managed. Otherwise the DW environment mission of being "the single version of the truth" becomes a myth. However, in data warehouse systems there are cases where developing an independent data mart is the only way to get the required figures out of the DW environment. Developing independent data marts, which are not 100% reconciled with the data warehouse environment and in most cases includes a supplementary source of data, must be clearly understood and all the associated risks must be identified.
Data marts are usually maintained and made available in the same environment as the data warehouse (systems like Oracle, Teradata, MS SQL Server, SAS) and are smaller in size than the enterprise data warehouse.
There are also many cases when data marts are created and refreshed on a server and distributed to the end users using shared drives or email and stored locally. This approach generates high maintenance costs, however makes it possible to keep data marts available offline.
There are two approaches to organize data in data marts:
Database datamart tables or its extracts represented by text files - one-dimensional, not aggregated data set; in most cases the data is processed and summarized many times by the reporting application.
Multidimensional database (MDDB) - aggregated data organized in multidimensional structure. The data is aggregated only once and is ready for business analysis right away.
In the next stage, the data from data marts is usually gathered by a reporting or analytic processing (OLAP) tool, such as Hyperion, Cognos, Business Objects, Pentaho BI, Microsoft Excel and made available for business analysis.
Usually, a company maintains multiple data marts serving the needs of finance, marketing, sales, operations, IT and other departments upon needs.
Example use of data marts in an organization: CRM reporting, customer migration analysis, production planning, monitoring of marketing campaigns, performance indicators, internal ratings and scoring, risk management, integration with other systems (systems which use the processed DW data) and more uses specific to the individual business.
================================================================================
SCD - Slowly changing dimensions
Slowly changing dimensions (SCD) determine how the historical changes in the dimension tables are handled. Implementing the SCD mechanism enables users to know to which category an item belonged to in any given date.
Types of Slowly Changing Dimensions in the Data Warehouse architectures:
Type 0 SCD is not used frequently, as it is classified as when no effort has been made to deal with the changing dimensions issues. So, some dimension data may be overwritten and other may stay unchanged over the time and it can result in confusing end-users.
Type 1 SCD DW architecture applies when no history is kept in the database. The new, changed data simply overwrites old entries. This approach is used quite often with data which change over the time and it is caused by correcting data quality errors (misspells, data consolidations, trimming spaces, language specific characters).
Type 1 SCD is easy to maintain and used mainly when losing the ability to track the old history is not an issue.
In the Type 2 SCD model the whole history is stored in the database. An additional dimension record is created and the segmenting between the old record values and the new (current) value is easy to extract and the history is clear. The fields 'effective date' and 'current indicator' are very often used in that dimension.
Type 3 SCD - only the information about a previous value of a dimension is written into the database. An 'old 'or 'previous' column is created which stores the immediate previous attribute. In Type 3 SCD users are able to describe history immediately and can report both forward and backward from the change.
However, that model can't track all historical changes, such as when a dimension changes twice or more. It would require creating next columns to store historical data and could make the whole data warehouse schema very complex.
Type 4 SCD idea is to store all historical changes in a separate historical data table for each of the dimensions.
In order to manage Slowly Changing Dimensions properly and easily it is highly recommended to use Surrogate Keys in the Data Warehouse tables.
A Surrogate Key is a technical key added to a fact table or a dimension table which is used instead of a business key (like product ID or customer ID).
Surrogate keys are always numeric and unique on a table level which makes it easy to distinguish and track values changed over time.
In practice, in big production Data Warehouse environments, mostly the Slowly Changing Dimensions Type 1, Type 2 and Type 3 are considered and used. It is a common practice to apply different SCD models to different dimension tables (or even columns in the same table) depending on the business reporting needs of a given type of data.
Reporting
A successful reporting platform implementation in a business intelligence environment requires great attention to be paid from both the business end users and IT professionals.
The fact is that the reporting layer is what business users might consider a data warehouse system and if they do not like it, they will not use it. Even though it might be a perfectly maintained data warehouse with high-quality data, stable and optimized ETL processes and faultless operation. It will be just useless for them, thus useless for the whole organization.
The problem is that the report generation process is not particularly interesting from the IT point of view as it does not involve heavy data processing and manipulation tasks. The IT professionals do not tend to pay great attention to this BI area as they consider it rather 'look and feel' than the 'real heavy stuff'.
From the other hand, the lack of technical exposure of the business users usually makes the report design process too complicated for them.
The conclusion is that the key to success in reporting (and the whole BI environment) is the collaboration between the business and IT professionals.
Types of reports
Reporting is a broad BI category and there is plenty of options and modes of its generation, definition, design, formatting and propagation.
The report types can be divided into several groups, illustrated below:
Standard, static report
Subject oriented, reported data defined precisely before creation
Reports with fixed layout defined by a report designer when the report is created
Very often the static reports contain subreports and perform calculations or implement advanced functions
Generated either on request by an end user or refreshed periodically from a scheduler
Usually are made available on the web server or a shared drive
Sample applications: Cognos Report Studio, Crystal Reports, BIRT
Ad-hoc report
Simple reports created by the end users on demand
Designed from scratch or using a standard report as a template
Sample applications: Cognos Analysis Studio
Interactive, multidimensional OLAP report
Usually provide more general information - using dynamic drill-down, slicing, dicing and filtering users can get the information they need
Reports with fixed design defined by a report designer
Generated either on request by an end user or refreshed periodically from a scheduler
Usually are made available on the web server or a shared drive
Sample applications: Cognos PowerPlay, Business Objects, Pentaho Mondrian
Dashboard
Contain high-level, aggregated company strategic data with comparisons and performance indicators
Include both static and interactive reports
Lots of graphics, charts, gauges and illustrations
Sample applications: Pentaho Dashboards, Oracle Hyperion, Microsoft SharePoint Server, Cognos Connection Portal
Write-back report
Those are interactive reports directly linked to the Data Warehouse which allow modification of the data warehouse data.
By far the most often use of this kind of reports is:
Editing and customizing products and customers grouping
Entering budget figures, forecasts, rebates
Setting sales targets
Refining business relevant data
Sample applications: Cognos Planning, SAP, Microsoft Access and Excel
Technical report
This group of reports is usually generated to fulfill the needs of the following areas:
IT technical reports for monitoring the BI system, generate execution performance statistics, data volumes, system workload, user activity etc.
Data quality reports - which are an input for business analysts to the data cleansing process
Metadata reports - for system analysts and data modelers
Extracts for other systems - formatted in a specific way
Usually generated in CSV or Microsoft Excel format
Reporting platforms
The most widely used reporting platforms:
IBM Cognos
SAP Business Objects and Crystal Reports
Oracle Hyperion and Siebel Analytics
Microstrategy
Microsoft Business Intelligence (SQL Server Reporting Services)
SAS
Pentaho Reporting and Analysis
BIRT - Open Source Business Intelligence and Reporting Tools
JasperReports
==================================================================================
Data mining
Data mining is an area of using intelligent information management tool to discover the knowledge and extract information to help support the decision making process in an organization. Data mining is an approach to discovering data behavior in large data sets by exploring the data, fitting different models and investigating different relationships in vast repositories.
The information extracted with a data mining tool can be used in such areas as decision support, prediction, sales forecasts, financial and risk analysis, estimation and optimization.
Sample real-world business use of data mining applications includes:
CRM - aids customers classification and retention campaigns
Web site traffic analysis - guest behavior prediction or relevant content delivery
Public sector organizations may use data mining to detect occurences of fraud such as money laundering and tax evasion, match crime and terrorist patterns, etc.
Genomics research - analysis of the vast data stores
The most widely known and encountered Data Mining techniques:
Statistical modeling which uses mathematical equations to do the analysis. The most popular statistical models are: generalized linear models, discriminant analysis, linear regression and logistic regression.
Decision list models and decision trees
Neural networks
Genetic algorithms
Screening models
Data mining tools offer a number data discovery techniques to provide expertise to the data and to help identify relevant set of attributes in the data:
Data manipulation which consists of construction of new data subsets derived from existing data sources.
Browsing, auditing and visualization of the data which helps identify non-typical, suspected relationships between variables in the data.
Hypothesis testing
A group of the most significant data mining tools is represented by:
SPSS Clementine
SAS Enterprise Miner
IBM DB2 Intelligent Miner
STATISTICA Data Miner
Pentaho Data Mining (WEKA)
Isoft Alice
==================================================================================
DATA FEDERATION
Try to remember all the times, when you had to collect data from many different sources. I guess, this reminds you all those situations when you have been searching and processing data for many hours, because you had to check every source one by one. After that it turns out that you had missed something and you spent another day attaching that missing data. However, there is solution, which can simplify your work. That solution is called “data federation”.
What is this and how does it work ?
Data federation is a kind of software that standardizes the integration of data from different (sometimes very dispersed) sources. It collects data from multiple sources, creates strategic layer of data and optimizes the integration of dispersed views, providing standardized access to those integrated view of information within single layer of data. That created layer ensures re-usability of the data. Due to that data federation has a very important significance while creating a SOA kind of software (Service Oriented Architecture - a computer system, where the main aim is to create software that will live up user’s expectations).
The most important advantages of good data federation software
Data federation strong points:
Large companies process huge amounts of data, that comes from different sources. In addition, with the company development, there are more and more data sources, that employees have to deal with and eventually it’s nearly impossible to work without using specific supportive software.
Standardized and simplified access to data – thanks to that even when we use data from different, dispersed sources that additionally have different formats, they can look like they are from the same source.
You can easily create integrated views of data and libraries of data store, that can be used multiple times.
Data are provided in real time, from original sources, not from cumulative databases or duplicates.
Efficient delivery of up-to-date data and protection of database in the same time.
Data federation weeknesses
There is no garden without weeds, so data federation also have some drawbacks.
While using that software, parameters should be closely watched and optimized, because aggregation logic takes place in server, not in the database. Wrong parameters or other errors can influence on the transmission or correctness of results. We should also remember that data comes from big amount of sources and it is important to check their reliability. Through using unproven and uncorrected data, we can have some errors in our work and that can cause financial looses for our company. Software can’t always judge if the source is reliable or not, so we have to make sure, that there ale special information managers, who watch over the correctness of data and decide what sources can our data federation application use.
As you can see, data federation system is very important, especially for big companies. It makes work with big amount of data from different sources much more easier.
Data federation - further reading on data federation
=====================================================================================
Data Warehouse metadata
The metadata in a data warehouse system unfolds the definitions, meaning, origin and rules of the data used in a Data Warehouse. There are two main types of metadata in a data warehouse system: business metadata and technical metadata. Those two types illustrate both business and technical point of view on the data.
The Data Warehouse Metadata is usually stored in a Metadata Repository which is accessible by a wide range of users.
Business metadata
Business metadata (datawarehouse metadata, front room metadata, operational metadata) - this type of metadata stores business definitions of the data, it contains high-level definitions of all fields present in the data warehouse, information about cubes, aggregates, datamarts.
Business metadata is mainly addressed to and used by the data warehouse users, report authors (for ad-hoc querying), cubes creators, data managers, testers, analysts.
Typically, the following information needs to be provided to describe business metadata:
DW Table Name
DW Column Name
Business Name - short and desctiptive header information
Definition - extended description with brief overiview of the business rules for the field
Field Type - a flag may indicate whether a given field stores the key or a discrete value, whether is active or not, or what data type is it. The content of that field (or fields) may vary upon business needs.
Technical metadata
Technical metadata (ETL process metadata, back room metadata, transformation metadata) is a representation of the ETL process. It stores data mapping and transformations from source systems to the data warehouse and is mostly used by datawarehouse developers, specialists and ETL modellers.
Most commercial ETL applications provide a metadata repository with an integrated metadata management system to manage the ETL process definition.
The definition of technical metadata is usually more complex than the business metadata and it sometimes involves multiple dependencies.
The technical metadata can be structured in the following way:
Source Database - or system definition. It can be a source system database, another data warehouse, file system, etc.
Target Database - Data Warehouse instance
Source Tables - one or more tables which are input to calculate a value of the field
Source Columns - one or more columns which are input to calculate a value of the field
Target Table - target DW table and column are always single in a metadata repository.
Target Column - target DW column
Transformation - the descriptive part of a metadata entry. It usually contains a lot of information, so it is important to use a common standard throughout the organisation to keep the data consistent.
Some tools dedicated to the metadata management(many of them are bundled with ETL tools):
Teradata Metadata Services
Erwin Data modeller
Microsoft Repository
IBM (Ascential) MetaStage
Pentaho Metadata
AbInitio EME (Enterpise Metadata Environment)
===================================================================================
Business Intelligence staffing
This study illustrates how global companies typically structure business intelligence resources and what teams and departments are involved in the support and maintenance of an Enterprise Data Warehouse.
This proposal may range widely across the organizations depending on the company requirements, the sector and BI strategy, however it might be considered as a template.
The successful business intelligence strategy requires the involvement of people from various departments. Those are mainly:
- Top Management (CIO, board of directors members, business managers)
- Finance
- Sales and Marketing
- IT - both business analysts and technical managers and specialists
Steering committee , Business owners
A typical enterprise data warehouse environment is under the control and direction of a steering committee. The steering committee sets the policy and strategic direction of the data warehouse and is responsible for the prioritization of the DW initiatives.
The steering committee is usually chaired by a DW business owner. Business owner acts as sponsor and champion of the whole BI environment in an organization.
Business Data Management group , Data governance team
This group forms the Business Stream of the BI staff and consist of a cross-functional team of representatives from the business and IT (mostly IT managers and analysts) with a shared vision to promote data standards, data quality, manage DW metadata and assure that the Data Warehouse is The Single Version of the Truth. Within the data governance group each major data branch has a business owner appointed to act as data steward. One of the key roles of the data steward is to approve access to the DW data.
The new DW projects and enhancements are shaped and approved by the Business Data Management group. The team also defines the Business Continuity Management and disaster recovery strategy.
Data Warehousing team
The IT stream of a Data Warehouse is usually the vastest and the most relevant from the technical perspective. It is hard to name this kind of team precisely and easily as it may differ significantly among organizations. This group might be referenced as Business Intelligence team, Data Warehousing team, Information Analysis Group, Information Delivery team, MIS Support, BI development, Datawarehousing Delivery team, BI solutions and services. Basically, the creativity of HR departments in naming BI teams and positions is much broader than you can imagine.
Some organizations also group the staff into smaller teams, oriented on a specific function or a topic.
The typical positions occupied by the members of the datawarehousing team are:
Data Warehouse analyst - those are people who know the OLTP and MIS systems and the dependencies between them in an organization. Very often the analysts create functional specification documents, high-level solution outlines, etc.
DW architect - a technical person which needs to understand the business strategy and implement that vision through technology
Business Intelligence specialist, Data Warehouse specialist, DW developer which are technical BI experts
ETL modeler, ETL developer - data integration technical experts
Reporting analyst, OLAP analyst , Information Delivery analyst, Report designer - people with analytical minds with some technical exposure
Team Leaders - by far the most often each of the Data Warehousing team subgroups has its own team leader who reports to a Business Intelligence IT manager. Those are very often experts who had been promoted.
Business Intelligence IT manager is a very important role because of the fact that a BI manager is a link between the steering committee, the data governance group and the experts.
DW Support and administration
This team is focused on the support, maintenance and resolution of operational problems within the data warehouse environment. The people included may be:
Database administrators (DBA)
Administrators of other BI tools in an organization (database, reporting, ETL)
Helpdesk support - customer support support the reporting front ends, accesses to the DW applications and other hardware and software problems
Sample DW team organogram
Enterprise Data Warehouse organizational chart with all the people involved and a sample staff count. The head count in our sample DW organization lists 35 people. Be aware that this organogram depends heavily on the company size and its mission, however it may be treated as a good illustration of proportions on the BI resources in a typical environment.
Keep in mind that not all positions involve full time resources.
Steering committee, Business owners - 3 *
Business Data Management group - 5
DW team - 20:
6 DW/ETL specialists and developers
3 report designers and analysts
6 DW technical analysts
5 Testers* (an analyst may also play the role of a tester)
Support and maintenance - 5*
===================================================================================
ETL process and concepts
ETL stands for extraction, transformation and loading. Etl is a process that involves the following tasks:
extracting data from source operational or archive systems which are the primary source of data for the data warehouse
transforming the data - which may involve cleaning, filtering, validating and applying business rules
loading the data into a data warehouse or any other database or application that houses data
The ETL process is also very often referred to as Data Integration process and ETL tool as a Data Integration platform.
The terms closely related to and managed by ETL processes are: data migration, data management, data cleansing, data synchronization and data consolidation.
The main goal of maintaining an ETL process in an organization is to migrate and transform data from the source OLTP systems to feed a data warehouse and form data marts.
ETL Tools
At present the most popular and widely used ETL tools and applications on the market are:
IBM Websphere DataStage (Formerly known as Ascential DataStage and Ardent DataStage)
Informatica PowerCenter
Oracle Warehouse Builder
Ab Initio
Pentaho Data Integration - Kettle Project (open source ETL)
SAS ETL studio
Cognos Decisionstream
Business Objects Data Integrator (BODI)
Microsoft SQL Server Integration Services (SSIS)
ETL process references
A detailed step-by-step instructions on how the ETL process can be implemented in IBM Websphere Datastage can be found in the Implementing ETL in DataStage tutorial lesson.
Etl process can be also successfully implemented using an open source ETL tool - Kettle. There is a separate Pentaho Data Integration section on our pages: Kettle ETL transformations




































